
The DEBS Grand Challenge is a series of competitions, that started in 2010, in which both academics and professionals compete with the goal of building faster and more accurate distributed and event-based system. Every year, the DEBS Grand Challenge participants have a chance to explore a new data set and a new problem and can compare their results based on the common evaluation criteria. The winners of the challenge are announced during the conference. The 2019 DEBS Grand Challenge focuses on the application of machine learning to LiDAR data. The goal of the challenge is to perform classification of objects in different scenes surveyed by the LiDAR. The applications of LIDAR and object detection go well beyond autonomous vehicles and are suitable for use in agriculture, waterway maintenance and flood prevention, and construction. The 2019 Grand Challenge evaluation platform is provided by the TU Dresden and the HOBBIT project, represented by AGT International. The HOBBIT project has received funding from the European Union’s H2020 research and innovation action program under grant agreement number 688227.
Participants of the challenge compete for two awards: (1) the performance award and (2) the audience award. The winner of the performance award will be determined through the automated evaluation via the HOBBIT platform, according to the evaluation criteria specified below. Evaluation criteria measure the speed and accuracy of submitted solutions. The winning team of the performance award will receive 1000 USD as prize money. The winner of the audience award will be determined amongst the finalists who present in the Grand Challenge session of the DEBS conference. In this session, the audience will be asked to vote for the solution with the most interesting concepts - the solution with the highest number of votes wins. The intention of the audience award is to highlight the qualities of the solutions that are not tied to performance. Specifically, the audience and challenge participants are encouraged to consider the following aspects:
There are two ways how teams can become finalists and get a presentation slot in the Grand Challenge session during the DEBS Conference: (1) two teams with the best performance (according to the evaluation via HOBBIT platform) will be nominated; (2) the Grand Challenge Program Committee will review submitted papers for each solution and nominate two teams with the most novel concepts. All submissions of sufficient quality that do not make it to the finals will get a chance to be presented at the DEBS conference as posters. The quality of the submissions will be determined based on the review process performed by the DEBS Grand Challenge Program Committee.
The data provided for the challenge consists of point cloud readings simulated for a LiDAR sensor that mounts 64 lasers, each shoot 1125 times per rotation. That is, each scene consists of 72,000 readings. Each reading is composed of attributes
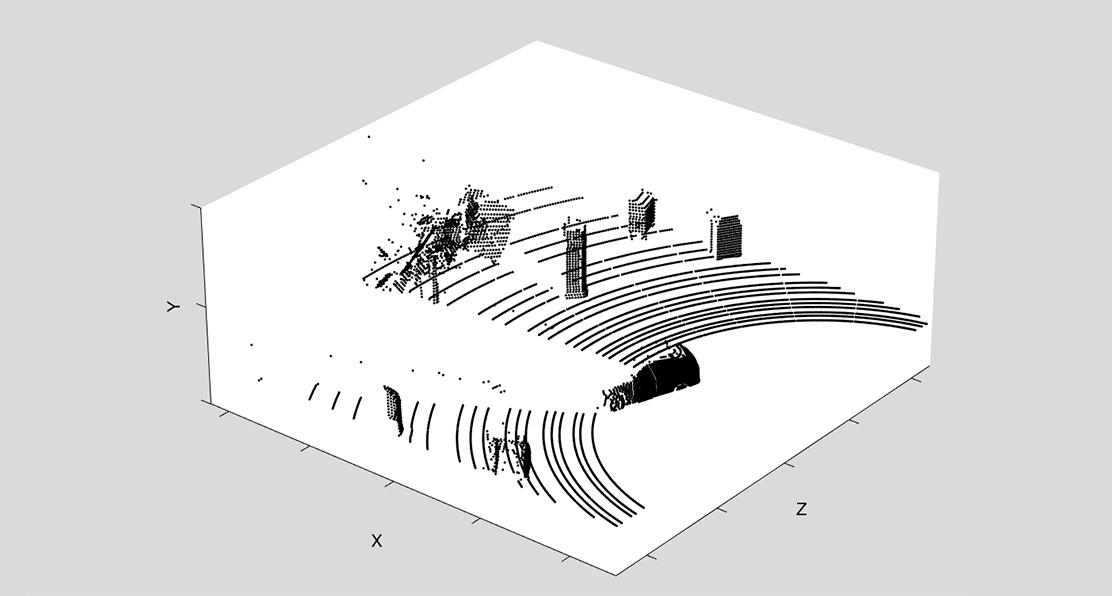
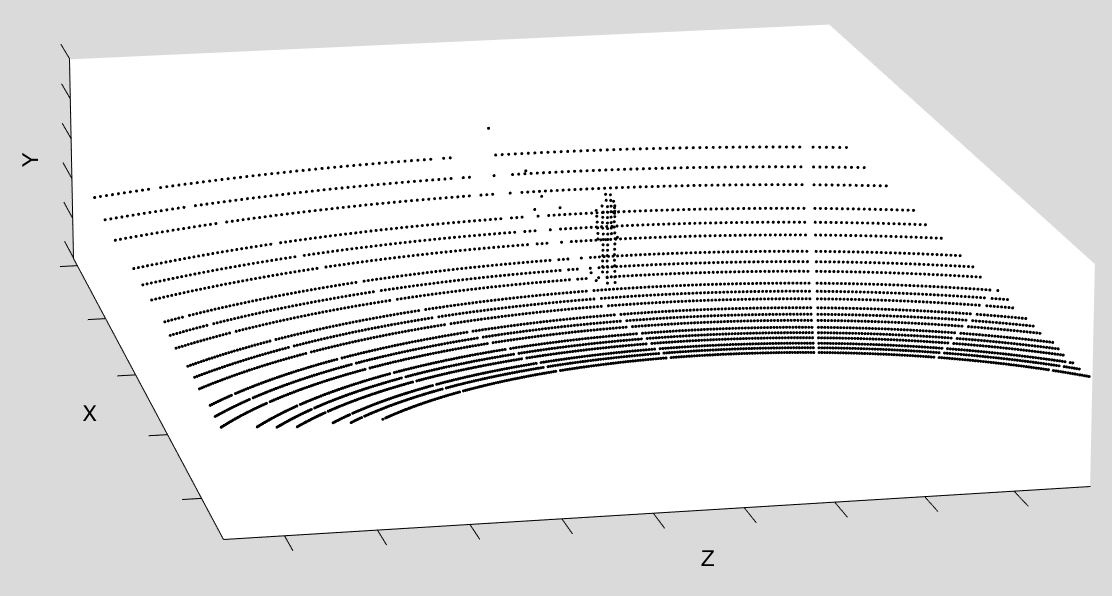
In each scene, the LiDAR is placed in the center of a given area and surrounded by a variable number of objects. Objects are representative of urban environments and are of the following types: ATM machine, pedestrian, benches, cloth recycling container, drinking fountain, electrical cabinet, emergency phone, fire hydrant, glass recycling container, ice freeze container, mailbox, trash bins, phone booth, trees, and several vehicle types. Please notice that, in some cases, it is possible for an object in a scene to be hidden from the LiDAR sensor (e.g., when such object is occluded by other objects in the scene). The overall number of different objects will be known upfront and fixed for the whole challenge duration. We will release the following datasets:
All released datasets contain the input data and
expected
output.
The initial dataset can be found here. It contains one zip file per individual object,
each
with 50
scenes plus a zip file called set1 with 100 scenes containing a variable number of
objects.
A bigger data set can be downloaded here. The bigger data set contains LiDAR data of 500 additional scenes, each containing 10 to 50 objects. To obtain the password for the data, please contact one of the co-organizers listed here. At this point, we strongly encourage you to register your team by pre-registering your submission in the EasyChair Grand Challenge track. This will allow us to send updates and announcements about the challenge to you via EasyChair.
Evaluation of the DEBS 2019 Grand Challenge addresses two aspects: (1) processing speed and (2) quality of results. We capture both aspects with multiple measures, each resulting in an individual ranking, i.e., rank_0, rank_1 for processing speed and rank_2, rank_3, and rank_4 for the quality of results. The overall final rank is calculated as the sum of all rankings: rank_0 + rank_1 + rank_2 + rank_3 + rank_4. The solution with the lowest overall final rank wins the performance award. The paper review score will be used in case of ties. The specifics of the ranking for the processing speed and quality of results are defined below.
We evaluate the processing performance through the total runtime (rank_0) and latency (rank_1). The total runtime (rank_0) is the time span between receiving the first scene from the input queue and submitting the classification results for the last scene. The lower the total runtime measure the higher the position in the ranking. The latency is (rank_1) measured as the average time span between retrieving a scene from the input queue and providing a classification for the scene averaged across all scenes n. The lower the latency the higher the position in the ranking.
Evaluation of the machine learning approach is based on the accuracy (rank_2), precision (rank_3), and recall (rank_4) as defined in [1]. Accuracy (rank_2) for each scene is defined as the proportion of the correctly predicted objects in the scene to the total number of predicted Yi and existing Zi objects in the scene. The accuracy is averaged across all scenes n:
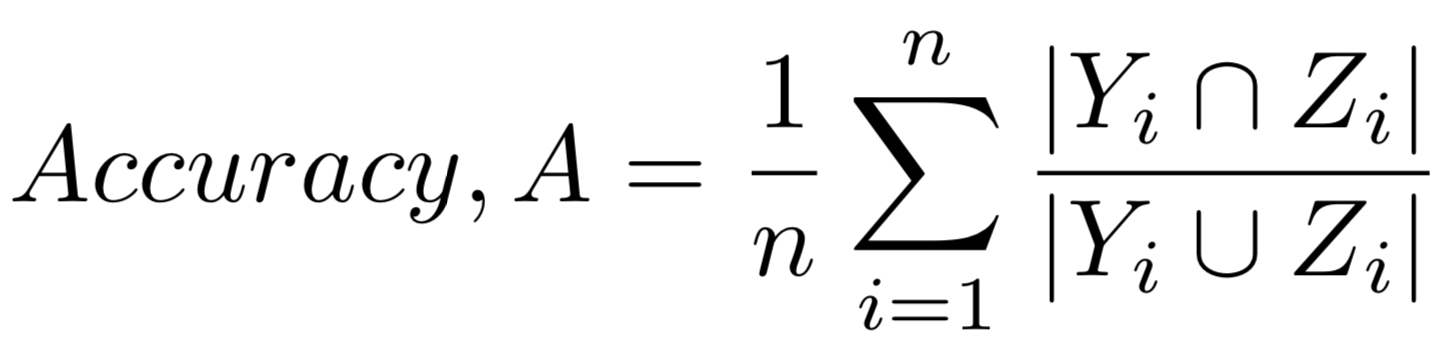
Precision (rank_3) is the proportion of correctly predicted objects to the total number of existing objects in the scene, averaged over all scenes n:
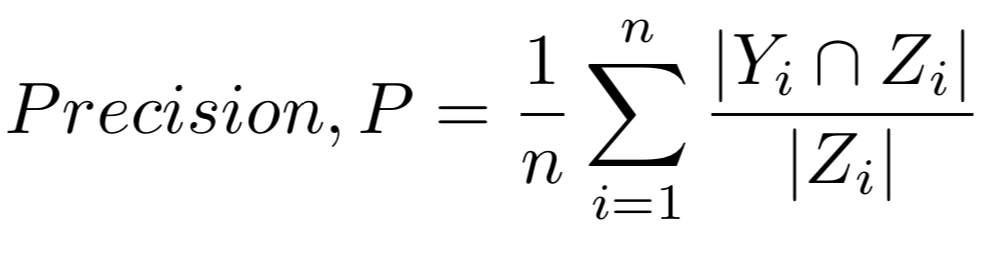
Recall (rank_4) is the proportion of correctly predicted objects to the total number of predicted objects Yi in the scene, averaged over all scenes n:
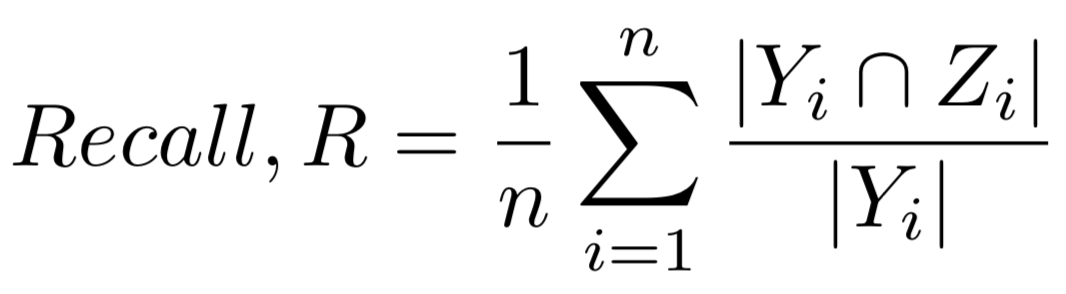
Our online evaluation system is up and running here. Instructions how to register your system for evaluation can be found in the github.
For local evaluation/testing you can download a docker compose based setup here. Questions regarding the data set and the evaluation platform should be posted in the issue tracker of the aforementioned git repository.
Participation in the DEBS 2019 Grand Challenge consists of three steps: (1) registration, (2) iterative solution submission, and (3) paper submission. The first step is to pre-register your submission in the EasyChair Grand Challenge track. Pre-registration in EasyChair is necessary to state the intent of a team to participate in the Grand Challenge and to establish the communication channel with the Grand Challenge organizers. At this step, it is sufficient to submit an interims title for your work. Solutions to the challenge, once developed, must be submitted to the evaluation platform (details will be provided later) in order to get it benchmarked in the challenge. The evaluation platform provides detailed feedback on performance and allows to update the solution in an iterative process. A solution can be continuously improved until the challenge closing date. Evaluation results of the last submitted solution will be used for the final performance ranking. The last step is to upload a short paper (minimum 2 pages, maximum 6 pages) describing the final solution to the EasyChair system. All papers will be reviewed by the DEBS Grand Challenge Program Committee to assess the merit and originality of submitted solutions. All solutions of sufficient quality will be presented during the poster session at the DEBS 2019 conference.
| Abstract and paper submission for research track |
|
| Research and Industry paper submission | |
| Tutorial proposal submission | |
| Grand challenge solution submission | |
| Author notification research track | |
| Poster, demo & doctoral symposium submission | |
| Early registration | May 31st, 2019 |
